
In a world where data is generated at ever-increasing rates, businesses are left with no choice but to keep up with the pace. Legacy data processing methods have become outdated and that’s where data streaming architecture comes in – the superhero that helps organizations process and analyze data as it’s generated, without waiting for batches to accumulate.
But what exactly is data streaming architecture?
In this article, we’ll look into the world of data streaming architecture – from its components and processes to its diagrams and applications. We’ll explore the sources of data, how it’s ingested and processed, and who gets to consume it.
We will also guide you on how to choose the right stream processing engine, message broker, data storage service, data ingestion tool , and data visualization and reporting tool for your specific use case.
By the end of this article, you’ll have a solid understanding of data streaming architecture and its role in the data-driven world we live in.
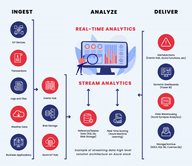
Data streaming refers to the practice of sending, receiving, and processing information in a stream rather than in discrete batches. It involves 6 main steps:
The first step in the process is when data is generated and sent from various sources such as IoT devices, web applications, or social media platforms. The data can be in different formats such as JSON or CSV and can have different characteristics such as structured or unstructured static or dynamic etc.
The data producers can use various protocols and methods to send the data to the consumers such as HTTP or MQTT push or pull etc.
In the second step, the data is received and stored by consumers such as streaming platforms or message brokers. These data consumers can use various technologies and streaming data architectures to handle the volume, velocity, and variety of the data such as Kafka or Estuary Flow streaming pipelines, etc.
The consumers can also perform some basic operations on the data such as validation or enrichment before passing it to a stream processor.
Click here to read about the many data integration options available.
Next, the data is analyzed and acted on by data processing tools . These tools can use various frameworks and tools to perform complex operations on the data such as filtering, aggregation, transformation, machine learning, etc.
Usually, the processing is tightly integrated with the platform that ingested the streaming data. Processing could be part of the platform itself, as with Estuary’s transformations . Or, you might pair a complementary technology with your streaming framework; for example, pairing Apache Spark with Kafka.
This is the step where data is further explored and interpreted by the analysts such as business users or data scientists. The analysts can use various techniques and methods to discover patterns and trends in the data such as descriptive analytics predictive analytics prescriptive analytics etc.
The analysts can also use various tools and platforms to access and query the data such as SQL or Python notebooks or Power BI etc. They can also produce outputs based on the analysis such as dashboards, charts, maps, alerts, etc.
To make sense of the analyzed data, it is summarized and communicated by reporting tools . The reports can be generated in various formats and channels to present and share the data with their stakeholders such as reports documents, emails slideshows or webinars, etc.
This step can also use various metrics and indicators to measure and monitor the performance of their goals, objectives, KPIs etc.
In the final step, data is displayed and acted upon by the decision-makers such as leaders or customers. The decision-makers can use various types and styles of visualizations to understand and explore the data such as tables, charts, maps, graphs, etc. They can also use various tools and features to interact with the visualizations such as filters, sorts, drill-downs, etc.
Based on the insights from the visualizations, the decision-makers can make timely decisions such as optimizing processes, improving products, enhancing customer experience, etc.
Now that we know the basic functionality of data streaming, let’s take a look at the key components of modern stream processing infrastructure.
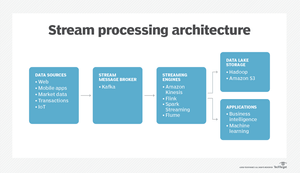
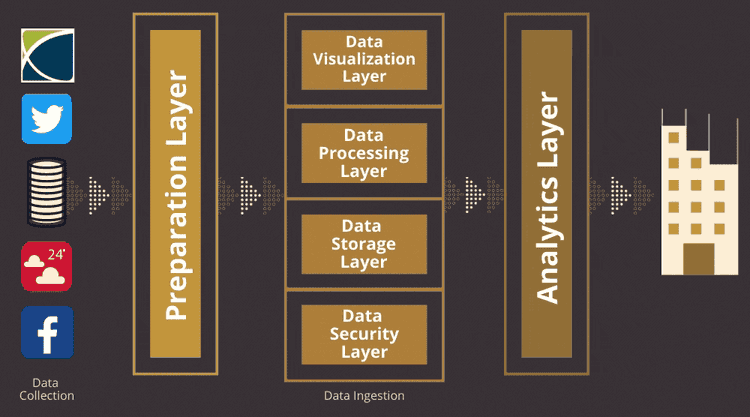
A modern data streaming architecture refers to a collection of tools and components designed to receive and handle high-volume data streams from various origins. Streaming data is data that is continuously generated and transmitted by various devices or applications, such as IoT sensors, security logs, web clicks, etc.
A data streaming architecture enables organizations to analyze and act on a data stream in real time, rather than waiting for batch processing.
A typical data streaming architecture consists of 5 main components :
This is the core component that processes streaming data. It can perform various operations such as filtering, aggregation, transformation, enrichment, windowing, etc. A stream processing engine can also support Complex Event Processing (CEP) which is the ability to detect patterns or anomalies in streaming data and trigger actions accordingly .
Some popular stream processing tools are Apache Spark Streaming, Apache Flink, Apache Kafka Streams, etc.
Honestly, there is no definitive answer to this question as different stream processing engines have different strengths and weaknesses and different use cases have different requirements and constraints.
However, there are some general factors that you must consider when choosing a stream processing engine . Let’s take a look at them:
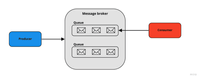
Message brokers act as buffers between the data sources and the stream processing engine. It collects data from various sources, converts it to a standard message format (such as JSON or Avro), and then streams it continuously for consumption by other components .
A message broker also provides features such as scalability, fault tolerance, load balancing, partitioning , etc. Some examples of message brokers are Apache Kafka, Amazon Kinesis Streams , etc.
With so many message brokers, selecting one can feel overwhelming. Here are factors you should consider when selecting a message broker for your data streaming architecture.
This component stores the processed or raw streaming data for later use. Data storage can be either persistent or ephemeral, relational or non-relational, structured or unstructured, etc. Because of the large amount and diverse format of event streams, many organizations opt to store their streaming event data in cloud object stores as an operational data lake . A standard method of loading data into the data storage is using ETL pipelines .
Some examples of data storage systems are Amazon S3, Hadoop Distributed File System (HDFS), Apache Cassandra, Elasticsearch, etc.
Read more about different types of data storage systems such as databases, data warehouses, and data lakes here .
There are various factors that you must consider when deciding on a data storage service. Some of these include:
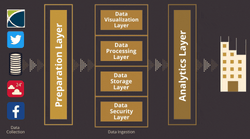
The data ingestion layer is a crucial part that collects data from various sources and transfers it to a data storage system for further data manipulation or analysis. This layer is responsible for processing different types of data, including structured, unstructured, or semi-structured, and formats like CSV, JSON, or XML. It is also responsible for ensuring that the data is accurate, secure, and consistent.
Some examples of data ingestion tools are Apache Flume, Logstash, Amazon Kinesis Firehose, etc.
There are many tools and technologies available in the market that can help you implement your desired data ingestion layer, such as Apache Flume , Apache Kafka, Azure Data Factory , etc.
Here are some factors that you can consider when selecting a tool or technology for your data ingestion layer:
While you can use dedicated data ingestion tools such as Flume or Kafka, a better option would be to use a tool like Estuary Flow that combines multiple components of streaming architecture. It includes data ingestion, stream processing, and message broker; and it contains data-lake-style storage in the cloud.
Estuary Flow supports a wide range of streaming data sources and formats so you can easily ingest and analyze data from social media feeds, IoT sensors, clickstream data, databases, and file systems.
This means you can get access to insights from your data sources faster than ever before. Whether you need to run a historic analysis or react quickly to changes, our stream processing engines will provide you with the necessary support.
And the best part?
You don’t need to be a coding expert to use Estuary Flow. Our powerful no-code solution makes it easy for organizations to create and manage data pipelines so you can focus on getting insights from your data instead of wrestling with code.
Data components that provide a user interface for exploring and analyzing streaming data. They can also generate reports or dashboards based on predefined metrics or queries. These components work together to form a complete data streaming architecture that can handle various types of streaming data and deliver real-time insights.
Some examples of data visualization and reporting tools are Grafana, Kibana, Tableau, Power BI, etc.
Here are some factors to consider when choosing data visualization and reporting tools for your data streaming architecture.
Now that we are familiar with the main components, let’s discuss the data streaming architecture diagram.
Data streaming architecture is a powerful way to unlock insights and make real-time decisions from continuous streams of incoming data. This innovative setup includes three key components: data sources that provide the raw information, pipelines for processing it all in an orderly manner, and finally applications or services consuming the processed results.
With these elements combined, you can track important trends as they happen.
With such information at their fingertips, the users can analyze it further through descriptive analysis which examines trends in historical data to predict what may happen next. Additionally, others choose to utilize predictive technology as well as prescription tactics, both crucial aspects of any business decision-making process.
There are many ways to design and implement a data streaming architecture depending on your needs and goals. Here are some examples of a modern streaming data architecture:
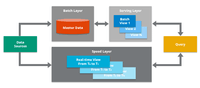
This is a hybrid architecture that uses two layers: a historical layer utilizing traditional technologies like Spark, then another for near-real time with quickly responding streaming tools such as Kafka or Storm.
These are unified together in an extra serving layer for optimal accuracy, scalability, and fault tolerance – though this complexity does come at some cost when it comes to latency and maintenance needs.
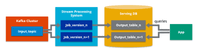
This is a simplified approach that uses only stream processing for both historical and real-time data . It uses one layer: a stream layer that processes all the incoming data using stream technologies such as Kafka Streams or Flink.
The processed data is stored in queryable storage that supports both batch and stream queries . This approach not only offers low latency, simplicity, and consistency but also requires high performance, reliability, and idempotency.
Data streaming architecture has become an essential component in the world of data processing and analysis. By utilizing streaming architecture, organizations can process streaming data in real-time to make informed decisions and take immediate action. As the volume and complexity of data continue to increase, data streaming architecture will undoubtedly become even more critical.
If you are ready to unlock the power of real-time data streaming for your business, it’s time to take action and try Estuary Flow . As a powerful data streaming platform, our tool can help you process and analyze data in real time. Sign up to try Estuary Flow free today and start experiencing the benefits of real-time data streaming for your business.